
Multi-Query Attention
Attention: 10 of 11

Multi-Query Attention (Shazeer, 2019) is an extension of Shared KV attention to the full multi-head setting.
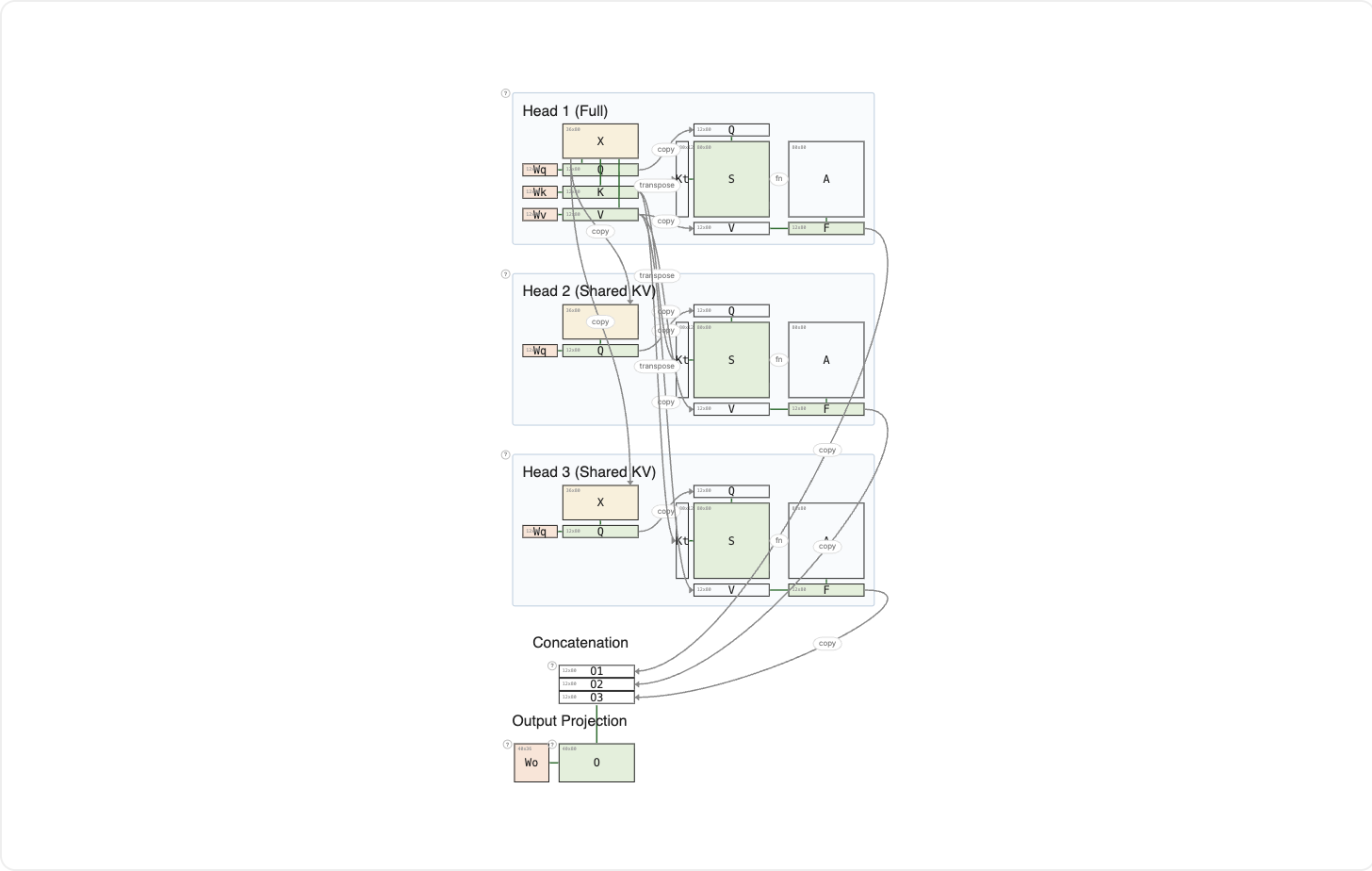
In standard Multi-Head Attention, every head has its own Q, K, and V. During autoregressive decoding, K and V from every previous token must be stored in a KV cache. With H heads, that cache is H times larger than a single head's.
MQA keeps H independent query heads but computes K and V just once. Each head can still ask a different question. But they all look up the answers in the same shared directory.
In this example, Head 1 is the full head: it computes Q, K, and V. Heads 2 and 3 each compute their own Q but reuse Head 1's K and V. The KV cache shrinks by a factor of H, with surprisingly little quality loss.