
Grouped-Query Attention
Attention: 11 of 11

Grouped-Query Attention (Ainslie et al., 2023) sits between Multi-Head Attention and Multi-Query Attention.
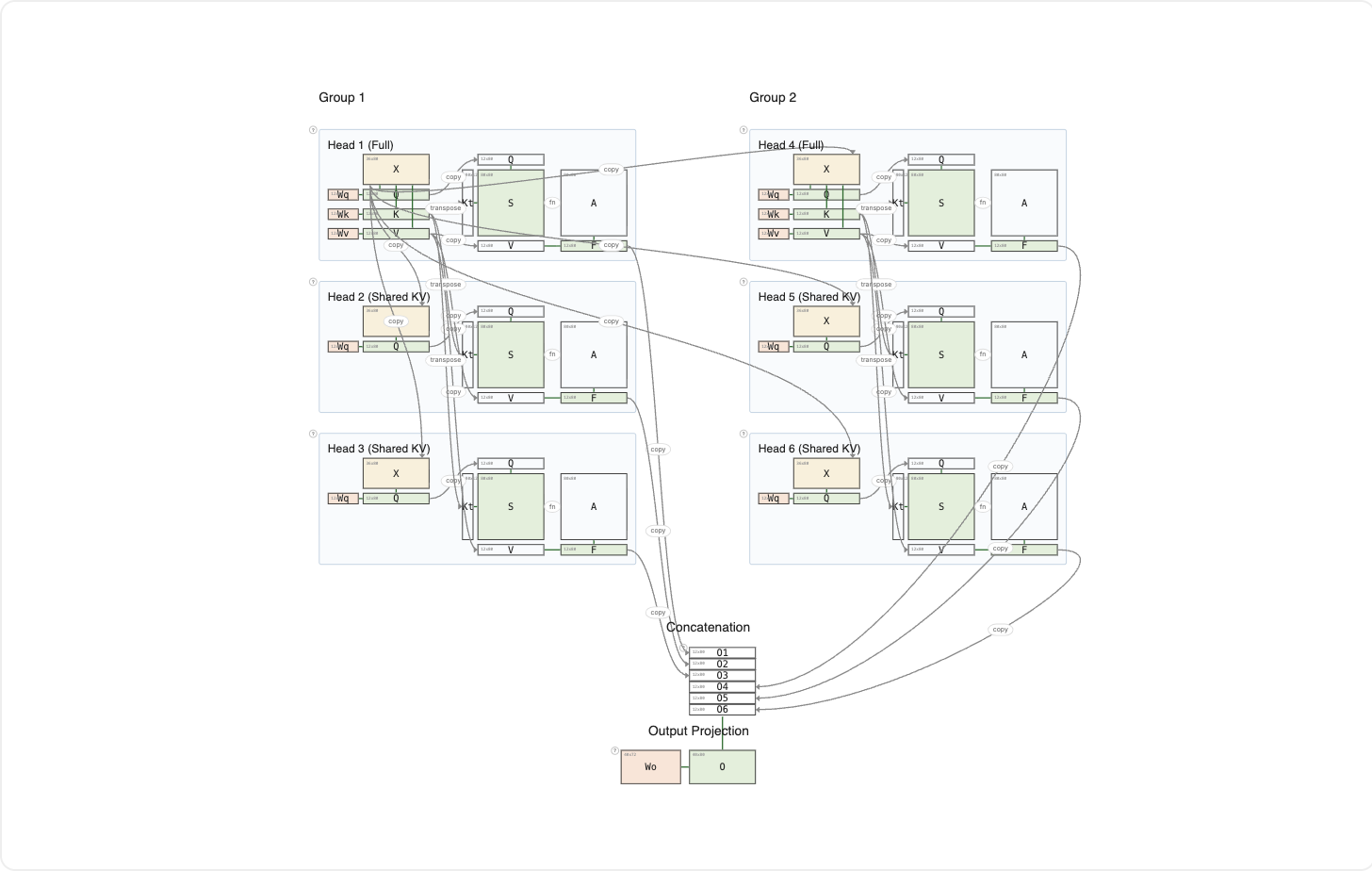
Think of the directory metaphor from the previous article. In MHA, each head has its own directory: maximum diversity, maximum cache cost. In MQA, every head shares one directory: minimal cache, but all heads look in the same place. GQA splits the difference: heads are divided into groups, and each group shares one directory.
This example has 2 groups of 3 heads each, for 6 heads total but only 2 sets of K and V. Within each group, one head computes K and V; the other two reuse them. Across groups, the two sets of K and V are independent, so different groups can still attend to different content.
GQA preserves most of MHA's expressive power while cutting the KV cache by the group size. Most production models today use GQA: Llama 3, Mistral, Gemma, and others all adopted it.