
Fused QKV (Multi-Head)
Attention: 8 of 11

Fused QKV is a structural rewrite of multi-head attention. Same math, different packaging.
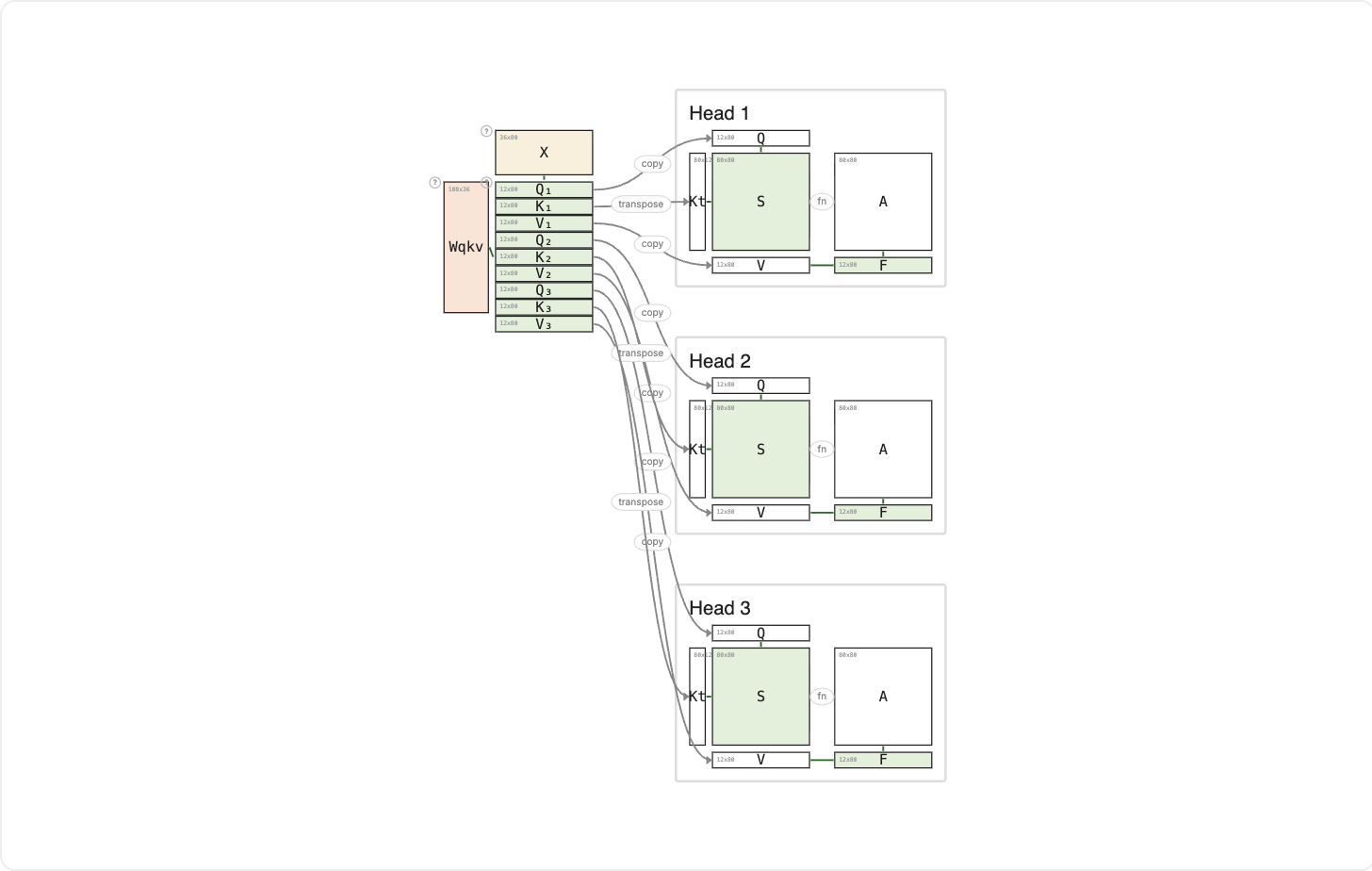
In standard multi-head attention, every head runs three independent matmuls (Wq × X, Wk × X, Wv × X), producing one Q, one K, and one V per head. With H heads, that's 3 × H small matmuls.
Fused QKV stacks every head's Wq, Wk, Wv vertically into one tall Wqkv weight matrix. A single matmul Wqkv × X then produces a single tall QKV matrix that simply partitions into the same per-head q–k–v triples.
Read the QKV output top-down: Q₁ K₁ V₁ Q₂ K₂ V₂ Q₃ K₃ V₃. One head's q, k, v appear as a contiguous block, repeated for every head. Once partitioned, each head runs its own attention scoring (Kᵀ × Q, softmax, V × A) exactly as before.
Why bother? Modern accelerators are far happier with one big matmul than 3H small ones. No accuracy difference: you get the same Q, K, V tensors as standard MHA, just produced with one launch instead of many. Think of it as compiling all your questions in one pass through the neighborhood, rather than going door to door separately for each head.