
Multi-Head Attention
Attention: 7 of 11

So far you have seen one head asking one question. Multi-Head Attention runs several heads in parallel, each asking a different question. One head might ask "who has a dog?", the midnight question you already know. Another might ask "who is still awake right now?" A third might ask "who lives close enough to hear the same bark?" Each head has its own learned Wq, Wk, and Wv, so each one attends to a different aspect of the input.
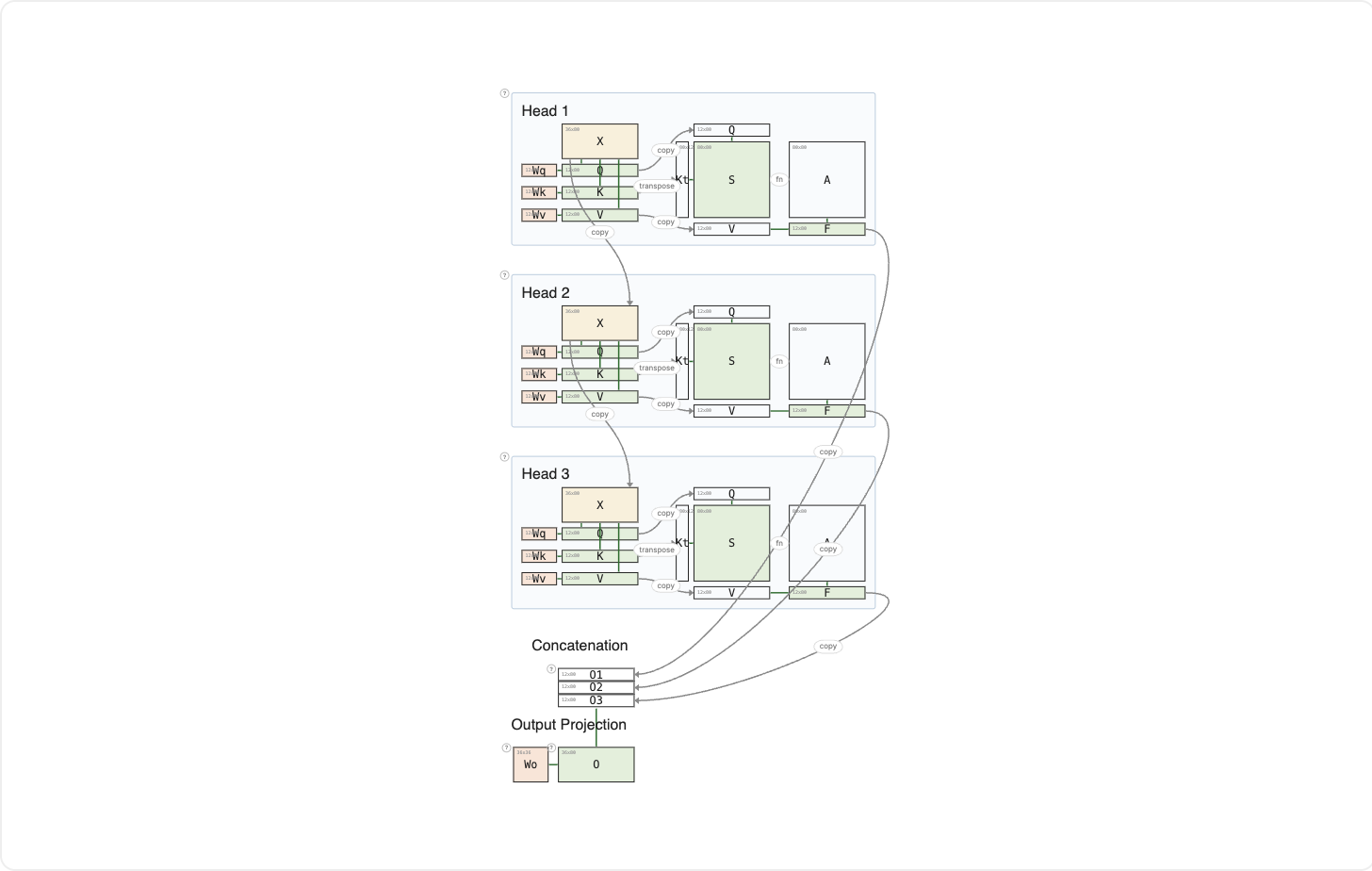
In this example, three heads run in parallel. Their outputs are concatenated and projected through a final weight matrix Wo to produce the result. The three heads each contribute a slice of the final representation.