
Self Attention
Attention: 3 of 11

Remember the midnight story from QKV Projection: a dog is barking, you can't sleep, and your query is "who has a dog?" There's one more thing: you also own a dog. Your own key has that same dimension lit up. So your query finds yourself too.
But pull back further: the whole neighborhood is awake. Every neighbor is lying in bed asking the exact same question: whose dog is barking at midnight? Every one of them has a query. Every one of them has a key and an address to give.
That's the "self" in self-attention: everyone queries, and everyone can be found. The result is a score for every (querier, neighbor) pair. There are N neighbors on the street, and each of them is also a querier. So the score matrix S is N × N: N rows of queries against N columns of keys, because the same N people play both roles.
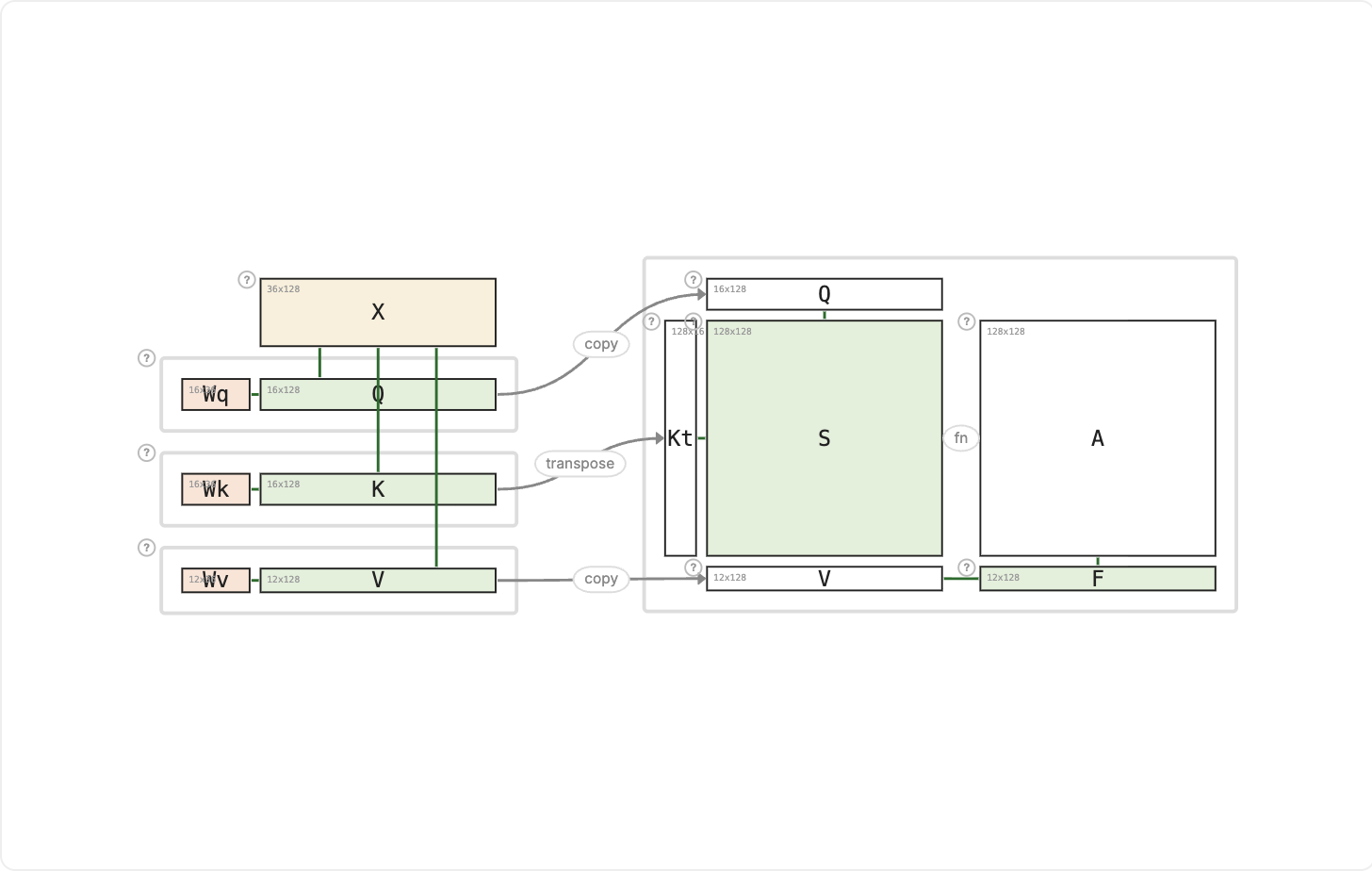
The input X is projected through three learned weight matrices (Wq, Wk, Wv) to produce Queries (Q), Keys (K), and Values (V). After scoring and softmax, the attention weights A select a weighted combination of Values to produce the output F = V × A.
Next:
4. Cross Attention